Example of a Continuous Time Series
Intro
Time series data is omnipresent in our lives. We can encounter it in pretty much any domain: sensors, monitoring, weather forecasts, stock prices, exchange rates, application performance, and a multicity of other metrics that we rely on in our professional and daily lives.
In this article, we will summarize all theoretical information about time series data. This basic knowledge is required for you to use time series data sets as a way to gain business insights or conduct a study. We will cover the main concepts related to gathering, organizing and usage of time series data. You will learn about the types and formats of time series data, ways to store and collect it. As well as diving into the fundamentals of analysis and visualization techniques explained on multiple time series data examples.
What is time series data?
Let's begin by clearly defining what time series data actually is, as well as what it isn't.
Basically, time series data is any type of information presented as an ordered sequence. It can be defined as a collection of observations for a single subject assembled over different, generally equally spaced, time intervals. Or, to put it simply, time series is data (observations or behavior) collected at different points in time and organized chronologically.
Time is the central attribute that distinguishes time series from other types of data. The time intervals applied to assemble the collected data in a chronological order are called the time series frequency. So having time as one of the main axes would be the main indicator that a given dataset is time-series.
Now, let's clarify what kinds of data are NOT time series to get this out of the way. Even though it is very common to use time as an axis in datasets, not all collected data is time-series. Data can be divided into several types based on time or, in other words, how and when it was recorded.
Here are three basic types of data, divided by the role of time in a dataset presentation:
- Time series data. As we learnt, time series data is collected over a specified continuous period of time.
- Cross-sectional data. This in many ways is an opposite concept to time series data, as cross-sectional databases rely on collecting and organizing various kinds of data at a single point in time.
- Pooled data. It's a term used when a combination of cross-functional and time series data is used.
How to identify such data
Since time series are used for multiple purposes and in various fields, the datasets can vary. Here are the three main characteristics that would allow you to easily identify such datasets:
- Data arrives in time order
- Time is a primary axis
- Newly collected data is recorded as a new entry
Why does it matter?
Being able to analyze and access insightful data is quickly becoming a necessity for almost any organization, including businesses, public and educational institutions. Time series data is a valuable commodity, and its value in today's world appreciates mightily.
It wouldn't be an overstatement to say that data—and our ability to collect and organize data with previously unseen speed and efficiency—is a key component of technological development. Being able to utilize gathered data allows us to build better systems, improve the efficiency of virtually all processes and predict future events in real time.
In today's world, time series data models are truly ubiquitous. Time-axed datasets are widely used across various industries, from finance and economics to sciences, healthcare, weather forecasting and engineering.
As data rapidly becomes one of the most valuable commodities in today's business world, the importance of time series datasets is increasing as well. Organizations across the globe face the need to implement more IT systems, sensors and tools, all of which are able to produce and/or collect time series data.
This is why it is so important to understand what time series data is, and how using it in the right way can allow an organization to improve and optimize virtually all work processes.
Since time is fundamental and the most integral part of our life, it plays a role in gathering any observable information. In other words, it won't be wrong to say that you can find it everywhere.
Examples and Applications
Being so omnipresent, time series obviously has a myriad of different applications across industries. In order for you to understand how it is used in practice, here are several examples.
- Industrial companies
Digitalization of manufacturing, production plants and related industries produces an increasing amount of time series data coming from a growing multicity of sensors. Examples of sensors producing time series data includes pressure, levels, temperature, pH and velocity used as part of industrial automation. - Financial industry
The absolute majority of financial/banking applications today collect, store and analyze time series data for multiple purposes, such as security, support, improvement of services, and income maximization. Needless to say, banks and financial institutions of various kinds rely on time series data heavily today. As another financial example, stock market traders use algorithms based on real time (time series) data to optimize performance. - Consumer electronics
Modern-day consumer electronics is an industry with a rapidly-growing appetite for data, mainly due to electronic devices and systems produced nowadays that are becoming more and more complex. Smart home systems, for example, have access to multiple kinds of time series data, which they analyze in order to identify humans and animals, adjust temperature, detect intruders, etc. Autonomous vehicles and robotic devices of various kinds also use time series data as an essential component that allows them to move in space and avoid collisions. - Healthcare
Time series data plays a vital role in healthcare as well. The COVID-19 epidemic is a great illustration of this: the collection of accurate and timely data played a vital role in allowing the global community to stay informed about the ongoing trends in COVID-19 statistics. In this case, time series data helps to save lives by allowing healthcare and government institutions to quickly react upon receiving the new information. There are many critical healthcare-related procedures that rely on time series data, such as heart rate monitoring (ECG) and brain monitoring (EEG). - Retail industry
Time series data is collected in various forms by the retail industry, allowing enterprises to monitor their supply and delivery chains with previously unseen efficiency. The data about moving of various goods enables retail enterprises to optimize stock and provide consumers with discounts or services such as same-day delivery. - Generic
Flow time series data, refers to focusing on measuring the activity of attributes over a given time period, which is typically an interval in the total time axis.
Stock time series data, on the other hand, is measuring attributes at a static point in time.
Types and Categorisation
Time series data can be divided into a number of types based on different criteria. Knowing the differences between the types of data is important as it affects the way you can interact with time series data and how the database can store and compress it. Let's go through some of the most common ways to categorize, illustrations and examples of time series data.
Metrics vs. events time series data
One characteristic of time series data that is important to understand is based on the relationship to the regularity of measurements collected in the series. Depending on whether the data is collected at regular or irregular time intervals, it can be classified as metrics or events.
Metrics is a type of measurement gathered at regular time intervals.
Events is a type of measurement gathered at irregular time intervals.
Metrics
Regular data that is evenly distributed across time and thus can be modeled or used for processes such as forecasting is called metrics. You need to have metrics in order to use modeling, forecasting and producing aggregates of all kinds.
Here are several examples of metrics.
Heart rate monitoring (ECG) and brain monitoring (EEG)
The above-mentioned heart rate monitoring, also known as electrocardiogram (ECG) and brain monitoring (electroencephalogram, EEG), as well as other similar health-related monitoring methods, are examples of metrics: they are measuring the activity of human organs at regular time periods.

Weather conditions
All kinds of weather conditions monitoring, such as daily temperature, wind, air pressure, heights of ocean tides, etc., is another example of metrics that are used to build data models, which allow us to predict weather changes that will occur in the future.

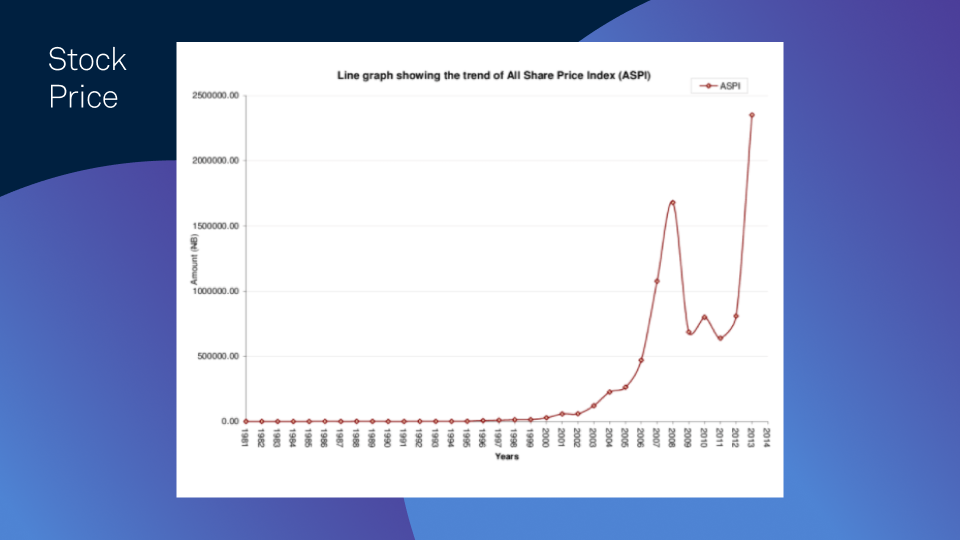
Stock price changes
Measurements of stock price fluctuations are also gathered at regular time intervals.
Events
Events measurements are gathered at irregular time intervals. Because they are unpredictable, intervals between events are inconsistent, which means that this data can't be used for forecasting and modeling as this would lead to unreliable future projections.
In simpler words, events are a type of data that is focused on capturing the required data whenever it is generated, which could happen with varying time intervals or as a burst.
Here are several examples of events.
Bank account deposits/withdrawals
Financial monitoring of bank accounts and ATMs is one example of events time series when the data gathered is the deposits and/or withdrawals, which typically occur at unpredictable time periods.

Computer logging
In computing systems, log files serve as a tool that records either various kinds of events that occur in an operating system and other software, or messages between different users of a communication software. Since all of this happens at irregular time intervals, the information in logs can be classified as events.

Linear vs. nonlinear time series data
Another way to classify it, is by the functional forms of data modeling, which divides it into linear and nonlinear.
In linear time series, each data point can be viewed as a linear combination of past or future values. In other words, a linear time series is generated by a linear equation and can be modeled as a linear AR (auto-regressive) model.
One way to specify if the time series is linear is by looking at how X and Y change in accordance to each other. When X increases by 1 and Y increases by a constant rate accordingly, then the data is linear.
Here's an example of a linear graph.

Nonlinear time series, on the other hand, are generated by nonlinear dynamic equations and have features that can't be modelled by linear processes, such as breaks, thresholds, asymmetric cycles and changing variances of different kinds. This is why generating and processing nonlinear time series data is typically a lot more difficult and requires complex modeling processes.
Here's one example of a nonlinear data:

How to work with time series data
Moving further, let's take a look at several key aspects of time series data that are important for you to understand in order to be able to work with and use it.
Immutability
One approach that is fundamental to time series data, and applied across all computing systems in general, is immutability. Which is quite a simple concept to understand.
Immutability is the idea that data (objects in functional programming languages) should not be changed after a new data record was created. Instead, all new records should only be added to the existing data.
Information updates in time series data models are always recorded as a new entry, coming in a time order. In line with the immutability principle, entries in time series data are usually not being changed after they were recorded and are simply added to all the previous records in a database.
So now it should be fairly easy to understand why immutability is a core concept to time series data. Time series database is always (or 'typically,' to be more precise) treated as a time-ordered series of immutable objects. Having immutability incorporated allows to keep time series databases consistent and unchanging as all queries are performed at a particular point-in-time.
Immutability as a core principle is something that differentiates time series data sets from relational data. As opposed to time series, the relational data, which is stored in relational databases, is typically mutable. It is used for online transaction processing and other requirements where new events take place on a generally random basis. Although these events still occur in chronological order (events of any kind just can't exist outside of time), time is not relevant to such data and therefore is not used as an axis. For time series data, on the other hand, time changes are always essential.
Data types
Now let's talk in more detail about the three basic types of data that we mentioned previously, and how time series data is different from cross-sectional, pooled and panel data. Understanding these concepts is another key element to being able to utilize time series data with multiple benefits.
As we learnt, time series data is a collection of observations for a single subject assembled over different time intervals. Having time as an axis is a distinctive feature of time series data.
Now let's compare it to cross-sectional and pooled/panel data.
Cross-sectional data
Cross-sectional data serves as an opposite concept, as this type relies on collecting and organizing various kinds of data at a single point in time. Cross-sectional data doesn't rely on natural ordering of the observations so the data can be entered in any order.
Data on max temperature, wind or humidity at any day in a year can be a good example of cross-sectional data. As well as closing prices of stocks on a stock market, or sales of a store inventory at any given day.

Pooled and panel data
Pooled (or cross-sectional) and panel (also called longitudinal) data are two rather close concepts, both used to describe data where time series and cross-sectional measurements are combined.
Essentially, both panel and pooled data rely on combining cross-sectional and time series measurements. The only difference is in the relationship to the units (entities), around which the data is collected (e.g. companies, cities, industries, etc.).
Panel data refers to multi-dimensional data that uses samples of the same cross-sectional units observed at multiple points in time.
Pooled data uses random samples of cross-functional units in different time periods, so each sample of cross-sectional data taken can be populated by different units.
How to tell the difference between time series, cross-sectional and pooled/panel data?
Undoubtedly, these data type explanations can still leave some people confused. Here's an easy way to differentiate these data types from each other.
- Time series are measurements on a single unit/entity over time.
- Cross-section are measurements on different units at a single point in time.
- If the data is presented both in multiple units and over a time period, it is panel or pooled data.
Data storage
Time series data is typically stored in time series databases (TSDBs) that are specifically built or optimized for working with timestamp data, be it metrics or events. Since time series data is frequently monitored and collected in huge volumes, it needs a database that can handle massive amounts of data.
TSDBs are also required to be able to support functions that are crucial to the efficient utilization of time series records, such as data summarization, data lifecycle management, and time-related queries.
Here is a list of features and capabilities that a modern purpose-built or optimized time series database should have:
- Support timestamps at different scales of precision (e.g. seconds, milliseconds, microseconds, or nanoseconds);
- Compression of variable levels in order to write high volumes of data;
- High throughout ingest and real-time querying;
- Retention policies for automatically removing the expired old time series;
- Time series data import capabilities and the ability to interact with SQL-like query languages;
- Built-in analytics, aggregation, filtering, interpolation, and smoothing functions for easy identification of trends or anomalies.
Top 10 most popular time series databases
Apache Druid
Apache Druid is an open-source column-oriented time series database designed for high-speed analytics applications that require fast ingestion of large amounts of data and the ability to run low-latency operational queries on that data with high concurrency.
The project to develop the Druid database was originally started in 2011 by four developers—Eric Tschetter, Fangjin Yang, Gian Merlino and Vadim Ogievetsky—who needed to create a database for the Metamarkets project. In 2012 the project was transferred to GPL open-source license, and moved to an Apache License in 2015. The database name, Druid, was inspired by the Druid class of characters in many role-playing games, reflecting the fact that the shape of this database can quickly change to address different types of data problems.
Nowadays Apache Druid is commonly used in high-load business intelligence applications to stream data from message buses such as Kafka or Amazon Kinesis, and to batch load files from data lakes such as HDFS or Amazon S3.
Apache Pinot
Apache Pinot is an open-source time series database designed to answer OLAP queries with low latency on immutable and mutable data.
The project to develop Apache Pinot was originally started by an internal team at LinkedIn with the goal to create a database that would meet the social network's requirements for rich real-time data analytics. It was open-sourced in 2015 under the Apache 2.0 license and donated to the Apache Software Foundation, which manages it now, in 2019.
Apache Pinot is a column-oriented database that supports compression schemes such as Run Length or Fixed Bit Length and pluggable indexing technologies like Sorted Index, Bitmap Index, or Inverted Index. It is able to ingest time series data from both batch (Hadoop HDFS, Amazon S3, Azure ADLS) and stream (Apache Kafka) data sources.
AWS Timestream
Amazon Timestream, part of Amazon Web Services (AWS), is a purpose-built time series database designed for collecting, storing, and processing time-series data in IoT and operational applications.
Fast time series data processing for real-time analytics is one distinctive feature of Amazon Timestream. The service was designed to provide 1,000 times faster query performance compared to relational databases, and includes features such as scheduled queries, multi-measure records, and data storage tiering. Automating scaling is another benefit of Amazon Timestream deriving from the cloud nature of this service. The solution scales automatically in accordance with the needs of user applications.
Amazon Timestream has SQL support with built-in time series functions for smoothing, approximation, and interpolation. It also supports advanced aggregates, window functions, and complex data types such as arrays and rows.The scheduled queries feature offers a serverless solution for calculating and storing aggregates, rollups, and other real-time analytics. Timestream queries are expressed in a SQL grammar with extensions for time series-specific data types and functions. Queries are then processed by an adaptive and distributed query engine that uses metadata from the tile tracking and indexing service to seamlessly access and combine data across data stores at the time the query is issued. Queries are run by a dedicated fleet of workers, the number of which is determined by query complexity and data size. Performance for complex queries over large data sets is achieved through massive parallelism, both on the query execution fleet and the storage fleets of the system.
Graphite
Graphite is an open-source database and monitoring solution designed for fast real-time processing, storage, retrieval and visualization of time series data. Originally developed by Orbitz Worldwide company in 2006, Graphite was released under the open source Apache 2.0 license in 2008.
Graphite is most commonly used in production and by e-commerce companies to track the performance of servers, applications, websites and software solutions. The tool relies on Whisper, a simple database library component, to store time series data. Graphite isn't a data collection agent, providing multiple easy integrations with third-party data tools instead. It uses Carbon as its primary backend daemon, which listens for any time-series data sent to the system and takes care of its processing. An additional Graphite webapp manages data visualizations, rendering graphs on-demand using Cairo library.
OpenTSDB
OpenTSDB is a distributed open-source time series database originally based on the Apache HBase open-source database. It is designed to address the need to collect, store and visualize time series data at a large scale. OpenTSDB is freely available under the GNU Lesser General Public License (LGPL) and GNU GPL licenses.
OpenTSDB was designed for maximum scalability, supporting the collection of time series data from tens of thousands of sources within an industrial automation network at a high rate. OpenTSDB databases consist of Time Series Daemons (TSD) and a set of command line utilities. TSDs run in each container and are responsible for redirecting newly collected data into the storage tier immediately upon its receival. Each TSD in an OpenTSDB database is independent from others and uses either HBase database or hosted Google Bigtable service to store and access time-series data. The communication with Time Series Daemons can be executed via a built-in GUI, an HTTP API, or using any telnet-style communication protocol.
InfluxDB
InfluxDB is an open-source time series database developed by InfluxData company and designed to handle large volumes of time-stamped data from multiple sources, including sensors, applications and infrastructure. InfluxDB uses Flux—fourth-generation programming language designed for data scripting, ETL, monitoring and alerting—as its query language.
Written in the Go programming language, InfluxDB was designed for high-performance time series data storage. InfluxDB can handle millions of data points per second and allows for high throughput ingest, compression and real-time querying. InfluxDB automatically compacts, compresses, and downsamples data to minimize storage costs, keeping high-precision raw data for a limited time and storing the lower-precision, summarized data for much longer. The InfluxDB platform comprises a multi-tenanted time series database, background processing, a monitoring agent, UI and dashboarding tools for data visualization.
InfluxDB's user interface includes a Data Explorer, dashboarding tools, and a script editor. Data Explorer allows users to quickly browse through the metric and collected event data, applying common transformations. The script editor is designed to help users quickly learn Flux query language with easily accessible examples, auto-completion and real-time syntax checking.
IBM Informix
IBM Informix is a family of relational database management system (RDBMS) solutions originally developed by Informix Corporation and designed for high-frequency OLTP (Online Transaction Processing) applications in industries such as manufacturing, retail, finance, energy and utilities, etc. In 2001, Informix database was acquired by IBM and is now a part of IBM's Information Management division. In 2017, IBM outsourced the maintenance and support of Informix to India-based HCL Technologies.
There are multiple editions of the Informix database, including free versions for developers, small and medium-sized businesses, etc. It is optimized for networks with low database administration capabilities, incorporating multiple self-management and automated administrative features.
IBM Informix supports the integration of time series, SQL, NoSQL, BSON, JSON, and spatial data. The database includes Informix TimeSeries feature designed for fast and easy work with time series data generated by various smart devices in IoT networks.
MongoDB
MongoDB is a non-relational document-oriented database designed for the storage of JSON-like documents and other types of unstructured data. The project to develop MongoDB was started by the 10gen company (which later changed its name to MongoDB Inc) in 2007. The database is currently licensed under the Server Side Public License (SSPL), a non-free source-available license developed by the project.
MongoDB supports field, range, and regular-expression queries, being able to return entire documents, specific fields of documents, or random samples in the query results. It uses sharding, a horizontal partition of data in a database, for load balancing and scaling. The data stored in a MongoDB database is split into ranges based on the shard key selected by the user, and gets distributed across different shards.
Replica sets are utilized by MongoDB to provide high availability of data stored in the database. Each replica set consists of two or more copies of the data, with every set member able to act as primary or secondary replica at any moment in time.
TimescaleDB
TimescaleDB is an open-source relational database for time-series data, built on top of PostgreSQL. It uses full SQL and is easy to use like a classic relational database, but is able to provide scaling and other features that are typically reserved for purpose-built NoSQL databases.
TimescaleDB was created as an all-in-one database solution for data-driven applications, providing users with a purpose-built time-series database combined with a classic relational (PostgreSQL) database with full SQL support. Accelerated performance is one of the main distinctive features of TimescaleDB. According to the developers, this database is able to run queries 10 to 100 times faster compared to PostgreSQL, InfluxDB, and MongoDB. They also claim TimescaleDB supports up to 10 times faster inserts and is able to ingest more metrics per second per server for high-cardinality workloads.
The ability to handle massive amounts of data is another key feature of TimescaleDB as it was designed to effectively record and store IoT data. TimescaleDB allows users to store hundreds of billions of rows and dozens of terabytes of data per server. The database uses data type‑specific compression, which allows it to increase storage capacity up to 16 times. Another key advantage of TimescaleDB is the support of both relational and time-series databases, which allows users to simplify their technology stacks and store relational data alongside time‑series data.
Prometheus
Prometheus is an open-source systems monitoring and alerting application originally created by SoundCloud, an online audio distribution platform and music sharing website. Prometheus collects and stores real-time metrics in a time series database. Time series collection is enabled by using a HTTP pull model. SoundCloud started developing Prometheus in 2012 as an open source project, upon realizing that existing monitoring tools and metrics are not fully applicable to their needs.
Prometheus databases store time series data in memory and on local disk in an efficient custom format. Scaling is achieved by functional sharding and federation. Prometheus's local storage is limited to a single node's scalability and durability. Instead of trying to solve clustered storage in Prometheus itself, Prometheus offers a set of interfaces that allow integrating with remote storage systems.
Prometheus provides a functional query language called PromQL (Prometheus Query Language) that lets the user select and aggregate time series data in real time. The results of their operations with data can be visualized as graphs or viewed as tabular data in Prometheus's expression browser. It can also be exported to external systems via the HTTP API.
Data (process) historians
Data or process historian (also sometimes being called operational historian or simply "historian") is a set of time-series database applications designed and typically used for collecting and storing data related to industrial operations. Read more about data historians.
Data historians were originally developed in the second half of the 1980s to be used with industrial automation systems such as SCADA (supervisory control and data acquisition). Primarily, they were utilized for the needs of the process manufacturing sector in industries such as oil and gas, chemicals, pharmaceuticals, pipelines and refining, etc.
Today, however, process historians are widely used across industries, serving as an important tool for performance monitoring, supervisory control, analytics, and quality assurance. They allow industrial facility managers and stakeholders, as well as engineers, data scientists and various machinery operators, to access the data collected from a variety of automated systems and sensors. The collected data can be utilized for performance monitoring, process tracking or business analytics. Modern-day historians also often include other features related to the utilization of collected data, such as reporting capabilities that allow users to generate automated or manual reports.
Time series analysis & data science
Now, after we learnt what time series data is and how it is stored, the next logical step would be to talk about the actual utilization of time series data models. This is where time series analysis comes into play.
What is time series analysis?
Time series analysis refers to a specific way of analyzing a time series dataset—or simply a sequence of data points gathered over a period of time—to extract insights, meaningful statistics and other characteristics of this data.
Naturally, time series analysis requires time series data, which has a natural temporal ordering and has to be recorded at consistent time intervals. This is something that differentiates time series analysis from cross-sectional data studies where data is tied to one specific point in time and can be entered in any order.
You should also not confuse time series analysis with forecasting, which is a type of time series analysis, as it basically uses historical TS datasets to make predictions using the same approach.
Patterns in time series analysis
Time series data analysis relies on identifying and observing patterns that serve as a way to extract actual information from a dataset using one of the available models.
Here are some of the most common patterns observed in time series data.
- Trend
A trend exists when there is a continuous and long enough change in data, be it upward or downward direction. Trends don't have to be linear and sometimes can be used to detect a change of direction. For example, increasing trend or decreasing trend would signal about a negative or positive change in sale of some item month-over-month. - Seasonality
A seasonal pattern is used when a time series data is affected by seasonal factors, which include all nature and weather-related influencers, such as season of the year, day of the month, time of day, etc. One feature of the seasonality pattern is that it always has pre-known and fixed frequency. - Cycle (cyclic behaviour)
As the opposite to seasonal pattern, cycle patterns occur when the data is affected by factors that are not of fixed and known frequency. This pattern is often applied in economy-related studies, where cyclic behaviour is observed in accordance to cycles in economy and business environment. The average length of cycles is usually longer than the length of seasonal patterns. The duration of cycles in time series data analytics typically is two years or more with a higher variable applied as well. - Anomaly/outlier
The detection of anomalies and outliers in time series datasets is essentially the opposite side of patterns, as the analysis is focused on identifying all kinds of unusual changes, desired or not, in the dataset. - White noise
Finally, in some cases the data doesn't follow any particular patterns with all the data units being in a seemingly random order. This kind of time series data pattern, or the absence of thereof to be precise, is called white noise.
Types of time series analysis
Detecting these and other patterns by applying various models to time series databases is how you can use time series analysis to achieve different goals.
Here are some of the most common types of time series analysis that can be utilized depending on the end-goal of your study.
Forecasting
As we learnt earlier, forecasting uses historical time series data to make predictions. Historical data is used as a model for the same data in the future, predicting various kinds of scenarios with future plot points.
Descriptive analysis
Descriptive analysis is the main method used to identify the above-described patterns in time series data (trends, cycles, and seasonality).
Explanative analysis
Explanative analysis models attempt to understand data, relationships between data points, what caused them and what was the effect.
Interrupted (intervention) analysis
Interrupted (intervention) time series analysis, also known as quasi-experimental analysis, is used to detect changes in a long-term time series from before to after a specific interruption (any external influence or a set of influences) took place, potentially affecting the underlying variable. Or, in simpler words, it studies how a time series data can be changed by a curtain event.
Regression analysis
Regression analysis is most commonly used as a way to test relationships between one or more different time series. As opposed to regression analysis, regular time series analysis refers to testing relationships between different points in a single time series.
Exploratory analysis
Exploratory analysis highlights main features identified in time series data, typically in visual format.
Association analysis
Association analysis is used to identify associations between any two features in a time series dataset.
Classification
Classification is used to identify and assign properties to time series data.
Segmentation
Segmentation analysis is applied to split the time series data into segments based on assigned properties.
Curve fitting
Curve fitting is used to study the relationships of different variables within a dataset by organizing them along a curve.
Data models
Now let's talk a little bit about models that are commonly used for time series data. There is a huge variety of models, representing different forms and stochastic processes. Not to get into too much detail, in this article we will only describe a few of the most popular and common models.
When looking at the process level, three broad classes of linear time series models should be specified.
Here they are:
- Autoregressive (AR) models
AR model is a representation of a type of random process, which is why it is used for data describing time-varying processes, such as changes in weather, economics, etc. - Integrated (I) models
Integrated models are series with random walk components. They are called integrated because these series are the sums of weakly-stationary components. - Moving-average (MA) models
Moving-average models are used for modeling univariate time series. In MA models, the output variable depends linearly on the current and various past values of an imperfectly predictable (stochastic) term.These three classes in various combinations produce the following three commonly used in time series data analytics models.
- Autoregressive moving average (ARMA) models
ARMA models combine AR and MA classes, where AR part involves regressing the variable on its own past values, while MA part is used to model the error term as a linear combination of error terms occurring contemporaneously and at various times in the past. ARMA models are frequently used for analytics and predicting future values in a series. - Autoregressive integrated moving average (ARIMA) models
ARIMA models are a generalization of an ARMA model and are used in cases where data show evidence of non-stationarity qualities, where an initial differencing step, corresponding to the integrated part of the model, can be applied one or more times to eliminate the non-stationarity of the mean function.Both ARMA and ARIMA models are frequently used for analytics and predicting future values in a series.
- Autoregressive fractionally integrated moving average (ARFIMA) models
ARFIMA model, in its turn, generalizes ARIMA models (or, basically, all the three basic classes) by allowing non-integer values of the differencing parameter. ARFIMA models are frequently used for modeling so-called long memory time series where deviations from the long-run mean decay slower than an exponential decay.When it comes to nonlinear time series models, there are a number of models that represent changes in variability over time that are predicted by or related to recent past values of the observed series.
- Autoregressive conditional heteroscedasticity (ARCH) models
ARCH is one such model, which describes the variance of the current error term or innovation as a function of the actual sizes of error terms.in the previous time periods.
Where to find time series datasets
In order to perform time series analysis, you would normally require a fairly large number of data points as a way to ensure reliability and consistency.
One problem that can limit your ability to utilize time series data for analytics, forecasting and other purposes is the absence of high-quality extensive datasets. This issue is easily solvable, however, as you can find a fair amount of time series data sets that include enormous volumes of data, publicly available online.
Here are several great sources where you can find large numbers of highly variable datasets.
- GitHub
GitHub is able to provide you with one of the widest and most diverse selections of time series databases on the internet. Here is one great list of topic-centric public data sources in high quality that can be found on GitHub. They are collected and tidied from blogs, answers, and user responses. Most of the datasets listed are free, but not all of them. Awesome time series database is one more great curated list of time series databases that are available for filtering based on language, backend, etc. - Federal Reserve Economic Data (FRED)
Federal Reserve Economic Data is another major source of publicly available datasets that you should check out if you need good quality time series data. FRED's library is totally free and contains hundreds of thousands of data series points collected from over 70 sources on various topics across countries and industries. - Google's dataset search engine
Chances are, you didn't know that the search giant Google has a dataset search service designed for the specific purpose of helping users to find publicly available data. It allows you to search by data formats, update dates, topics, types of licenses and so on. The datasets you will find by using Google's search will be smaller in size in most cases, but still useful for creating time series models. - UEA & UCR Time Series Classification Repository
UEA & UCR Time Series Classification Repository is an ongoing project aiming to develop a comprehensive repository for research into time series classification. Currently TSC archive has 128 huge datasets that are all free and publicly available. - Kaggle
Kaggle is the world's largest data science community that has a total of over 50,000 public datasets and 400,000 public notebooks available. Kaggle also has its own dataset search engine with thousands of publicly available time series datasets being indexed. - CompEngine
CompEngine is a self-organizing database of time-series data, which allows you to upload time-series data and interactively visualize similar data that have been measured by others. With CompEngine, you can not only find great time series datasets, but also use a specialized time series data comparison engine, which allows users to upload their own data and visualize how it relates to time series data measured and generated by others. In total, CompEngine's repository has almost 30,000 time series datasets with over 140 mln data points. - Data portals
Data portals is a comprehensive list of open data portals from around the world. Currently, it has 591 data portals that mostly belong to government and public institutions of various kinds.
How to create time series datasets
Despite having all these wonderful sources of time series data around the world, depending on your specific needs, you may still face a challenge of not having enough data. In such a case, the only solution would be to create your own time series dataset.
Now, creating and using time series datasets is a very broad topic that would require an extensive guide or tutorial on its own to cover all the aspects of this work. We can say, however, that collecting time series data, generating datasets and utilizing them for various purposes gets easier day by day thanks to a number of great libraries and frameworks that are designed to make it easier to work with time series data.
Best Python libraries for simpler creation and usage of time series datasets
Let's take a look at several great Python libraries and packages that you can use to create time series datasets, as well as using them afterwards to build models, generate predictions, etc.
- Timeseries Generator
A repository of python packages to generate synthetic datasets in a generic way from Nike open-source. Generate data based on many factors such as random noise, linear trend, seasonality or a combination of these factors. The package also provide a web-based UI to generate datasets in an interactive web UI. - Pandas
Pandas is another Python library created for various data manipulation and analysis purposes. Pandas provides you with tools for reading and writing data between in-memory data structures and different file formats, supports data alignment, integrated handling of missing data, reshaping and pivoting of data sets. It also allows various other kinds of time series data manipulation operations such as merging, selecting, as well as data cleaning, and data wrangling. - TSFRESH
TSFRESH or Time Series Feature is a Python package that contains many feature extraction methods and a robust feature selection algorithm. TSFRESH is able to automatically extract hundreds of features from a time series. Those features describe basic characteristics of the time series such as the number of peaks, the average or maximal value or more complex features such as the time reversal symmetry statistic. These sets of features can then be used as datasets to construct statistical or machine learning models on the time series. - TimeSynth
TimeSynth is an open source Python library for generating synthetic time series for model testing. The library can generate regular and irregular time series. The architecture enables users to match different signals with different architectures, allowing a vast array of signals to be generated.
- PyFlux
PyFlux is an open source time series library for Python. The library has a good array of modern time series models, as well as a flexible array of inference options that can be applied to these models. By combining breadth of models with breadth of inference, PyFlux allows for a probabilistic approach to time series modelling. - Cesium
Cesium is an open source library that allows users to extract features from raw time series data, build machine learning models from these features, and generate predictions for new data.
Time series data visualization
Another crucial element of utilizing time series data is visualization. In order to extract valuable information and insights, your data has to be presented as temporal visualization to showcase the changes at different points in time.
Time series data visualization is typically performed with specialized tools that provide users with multiple visualization types and formats to choose from. Let's take a look at some of the most common data visualization options.
What is time series graph?
Graph is a visual representation of data in an organized manner. Time series graphs, also called time series charts or time series plots, are probably the most common data visualization instrument used to illustrate data points at a temporal scale where each point corresponds to both time and the unit of measurement.
Are time series graphs and time series charts the same thing?
Even though these two terms are frequently used interchangeably, they are not exactly the same thing. Charts is the term for all kinds of representations of time series datasets in order to make the information clear and more understandable. Graphs, being mathematical diagrams showing the relationship between the data units over a period of time, are commonly used as a type of charts when visualizing time series data.
What is a real time graph?
Real time graphs, also known as data streaming charts, are used to display time series data in real time. This means that a real time graph will automatically update after every several seconds or when the new data point is received from the server.
Here are some of the most common types of time series visualizations.
Line graph
Line graph is probably the most simple way to visualize time series data. It uses points connected to illustrate the changes. Being the independent variable, time in line graphs is always presented as the horizontal axis.

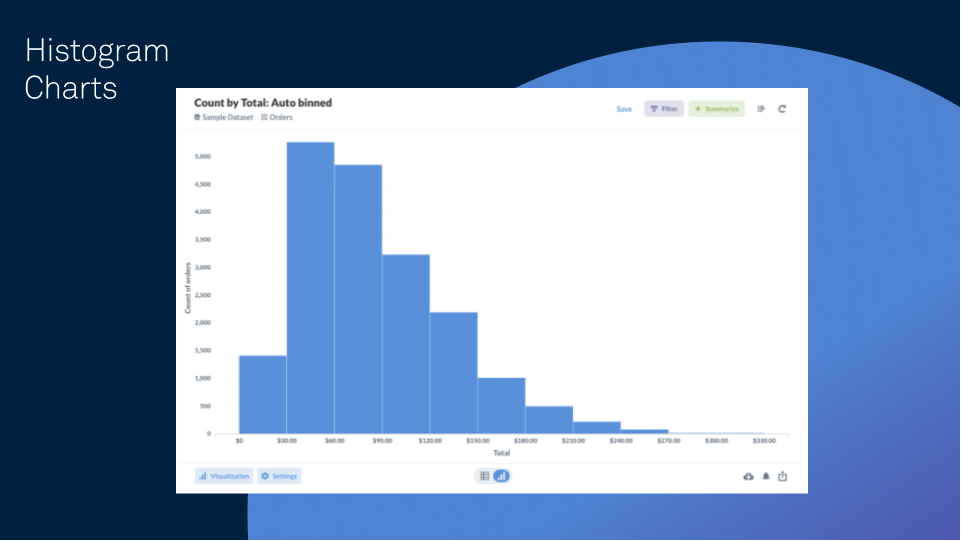
Histogram charts
Histogram charts visualize time series data by grouping it into bins, where bins are displayed as segmented columns. All bins in a histogram have equal width while their height is proportional to the number of data points in the bin.
Dot plots
Dot plots or dot graphs present data points vertically with dot-like markers, with the height of each marker group representing the frequency of the elements in each interval.

Scatter plots
Scatter plots or charts use the same dot-like markers that are scattered across the chart area of the plot, representing each data point. Scatter plots are usually used as a way to visualize random variables in time series data.

Trend line
Trend line is based on standard line and plot graphs, adding a straight line that has to connect at least two points on a chart, extending forward into the future to identify areas of support and resistance.

Tools to visualize time series data
Time series data can be translated into charts, graphs, and other kinds of consumable analytical information that provides organizations with (often invaluable) insights. Time series visualization tools, which can come in the form of software or SaaS solutions, are required to analyze and present the data in a digestible form.
Time series data visualization tools allow organizations to create dashboards with easy to understand visualizations of key trends and KPIs. It is also increasingly common for modern data visualization solutions to have a simple drag-and-drop interface, allowing users with no technical and/or coding skills to work with time series data and create dashboards. These tools are typically designed specifically to visualize already organized time series data and are not intended to be used for time series data analysis. Some of them, however, may include additional features, allowing users to perform multiple types of activities, such as exploring, organizing and interacting with data, as well as collaborating and sharing data between members of the same organization.
When choosing a data visualization tool for use, check if it meets all the main general requirements for such a solution:
- Supports data import from a wide range of sources, including database querying, application connectors, and file uploads;
- Has a user-friendly and simple to use visual no-code interface for interactions with data;
- Provides visual presentation of all KPIs in real time;
- Allows multiple users to work on the same datasets and visualizations at the same time;
- Enables easy export of all your data to multiple channels, including directly to Excel and via API;
- Offers multiple kinds of visualizations for time series data metrics.
Top 5 best data visualization tools
Here's a list of the best tools for your time series data visualization based on the requirements listed above.
- Clarify
Clarify is a powerful time series intelligence tool designed primarily for industrial teams. Clarify combines a number of features, allowing users to integrate, organize, collaborate and visualize industrial data. It supports a streaming data timeline technology that allows users to quickly navigate and visualize hundreds of data signals at the same time without losing overview or performance.This tool has extensive collaboration capabilities, which is one of its main distinctive features. It allows team members to tag each other to start a thread or log incidents, directly in the data timeline. Adding media files for more context, search and review of previous activities to avoid solving the same issue twice are some of other convenient features of Clarify. Developer-friendly documentation and secure APIs make it easy and secure to work with this solution as well.
- Microsoft Power BI
Power BI (a part of Microsoft Power Platform) is a business analytics service from Microsoft that provides users with interactive visualizations and business intelligence capabilities. It has a simple visual interface allowing users with no technical knowledge to create their own reports and build dashboards. Power BI allows you to easily connect to, model, and visualize data, and has additional features such as end-to-end data protection, a big library of data connectors, and simplified data sharing across Microsoft Office applications such as Microsoft Teams and Excel. - Grafana
Grafana is an open source multiplatform analytics and monitoring solution that supports a number of interactive visualization features. Grafana provides users with charts, graphs, and alerts for the web when connected to supported data sources.Unified approach to data that allows users to import it from various sources, including Kubernetes cluster, raspberry pi, different cloud services, and Google Sheets, is another notable feature of Grafana. It allows users to easily create dynamic dashboards, work on time series data in collaboration with other people and share visualized data with team members.
- Seeq
Seeq is a specialized application for process data analytics. It allows users to search their data, add context, cleanse, model, find patterns, establish boundaries, monitor assets, collaborate in real time, and interact with time series data in other ways. One of Seeq's distinctive features is the support of easy data integration from multiple platforms and databases, including legacy solutions. In particular, Seeq supports integration with Honeywell PHD, GE Proficy, as well as the PI System and relational data from SQL Server, Oracle, and MySQL. Users can access and combine different datasets from multiple sources without the need to write code. - Azure Time Series Insights
Azure Time Series Insights is a fully managed analytics, storage, and visualization service that is designed to make it easier to explore and analyze data related to IoT events. It provides users with a global view of their data for quick validation of IoT solutions to avoid costly downtime of mission-critical devices.Azure Time Series Insights is able to store, visualize, and query large amounts of time series data in general, whether they are related to IoT events or not. This solution allows you to collect streams of data from multiple IoT devices, easily integrate it into the platform, store and access it. Azure Time Series Insights also includes rich graphic visualizations and tools to conduct deep analysis into IoT data. Open APIs allow users to connect time series data to machine learning solutions or other visualization systems.
Final words
Hopefully, this article helped you to gain a better understanding of the fundamentals of time series data. Today, being aware about the true value of data is crucially important. You have probably heard the phrase "data is the new gold." In the current era of digital transformation and Industry 4.0/5.0 solutions, the ability to collect, store and use time series data is one of the decisive factors and keys to business success.
Clarify is a solution that provides industrial teams with a next-gen level of time series data intelligence, helping to make data points from data historians, SCADA and IoT devices useful for the whole workforce, from field workers to data scientists.
Clarify makes it easy to visualize time series data from your IoT network, access it on web and mobile devices, share data amongst teammates and collaborate on it in real time. With Clarify, your organization can focus on key business goals instead of configuring dashboards or developing expensive custom solutions.
templetonopetchas.blogspot.com
Source: https://www.clarify.io/learn/time-series-data